
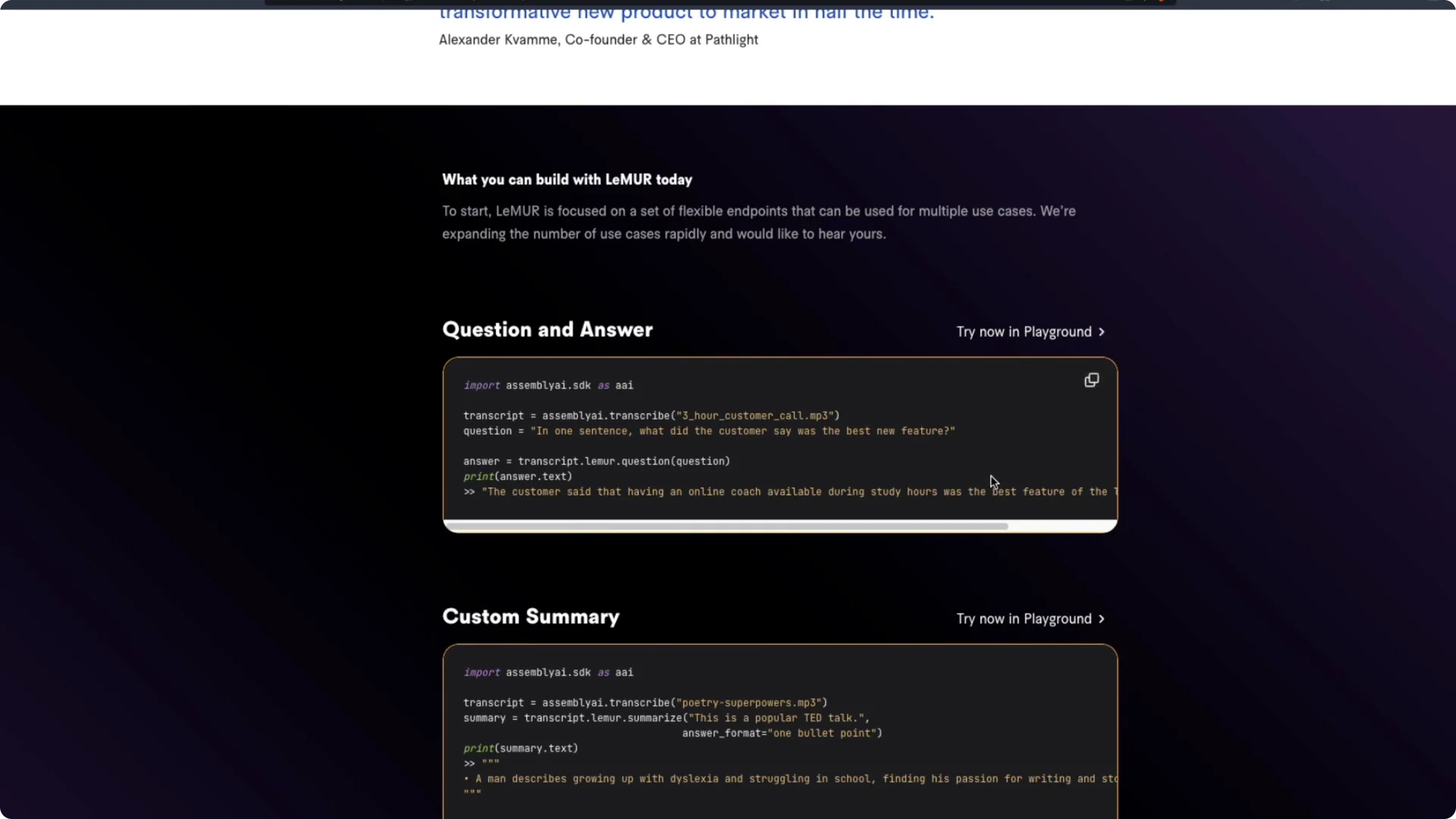
Imagine you have 10 hours of audio and you want to ask questions using a large language model. That usually means setting up a vector database and a lot of plumbing. AssemblyAI has a new framework called LeMUR that applies large language models to transcribed speech.
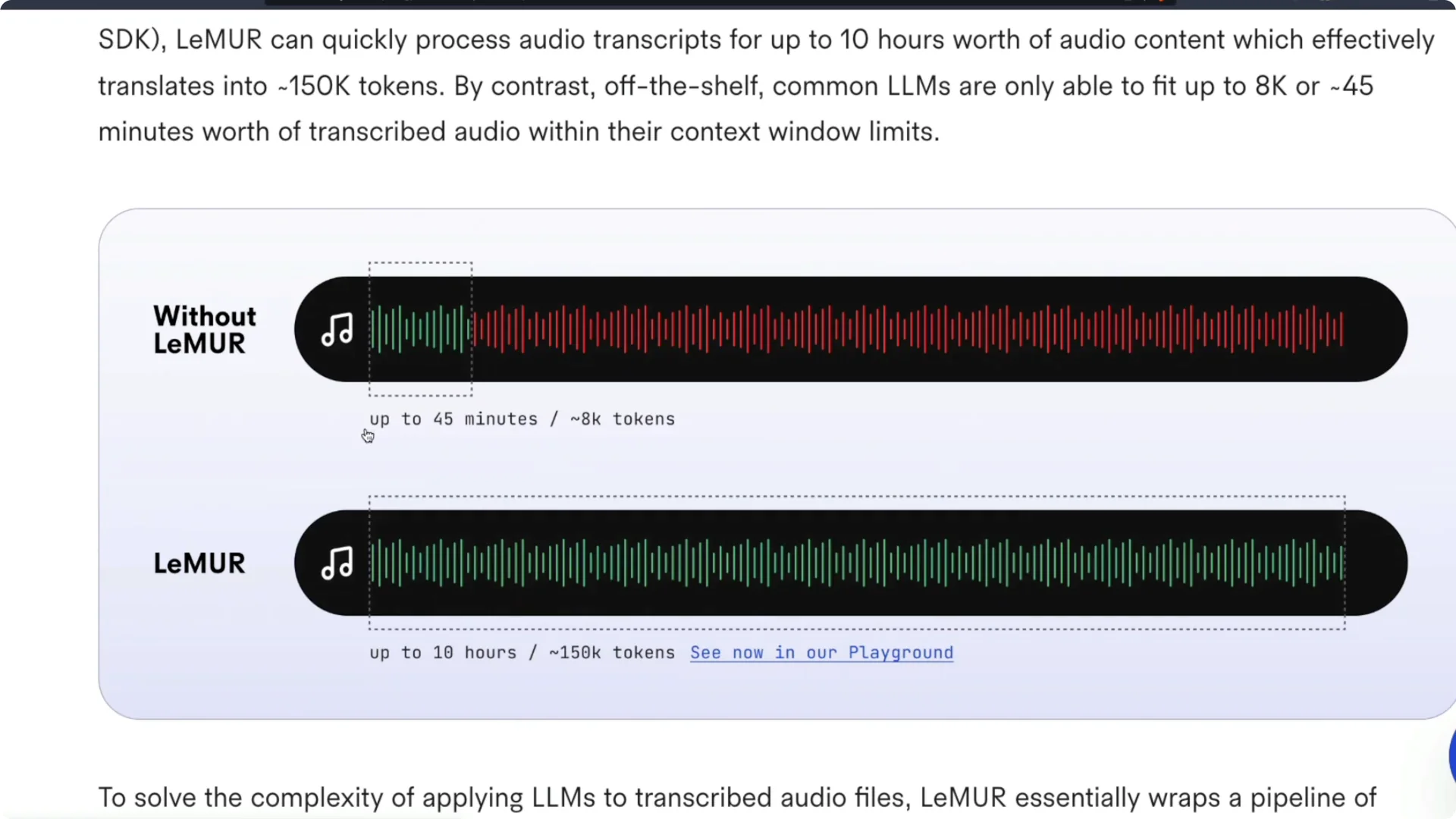
With LeMUR, you can transcribe a 10-hour audio clip and run summarization, question answering, and more on the transcript. The effective context handled is around 150,000 tokens. That opens up tasks that were previously hard to do with one system.
LeMUR is not fully released as a public model yet. You need to join a waiting list. There is a playground where you can try it.
What the AssemblyAI LeMUR Framework does
LeMUR is a framework for applying large language models to transcribed speech with a single line of code. It can process about 10 hours of audio content, which translates to roughly 150,000 tokens for tasks like summarization and Q&A. Typical context windows are far smaller, so this approach changes what you can run on long transcripts.
Without LeMUR, you can process about 45 minutes of audio with an 8,000 token context window. With LeMUR, you can work with around 10 hours of audio content. That is a big jump in practical context.
If you prefer a local workflow for speech-to-text before sending chunks to an LLM, you can use OpenAI Whisper. For a quick start, see this Python walkthrough for Whisper.
How the AssemblyAI LeMUR Framework handles long audio
LeMUR does not rely on a single massive context window. It uses an intelligent pipeline that includes transcription, segmentation, retrieval, and reasoning to compose accurate answers. The important part is you interact with one API call while the system handles the hard parts.
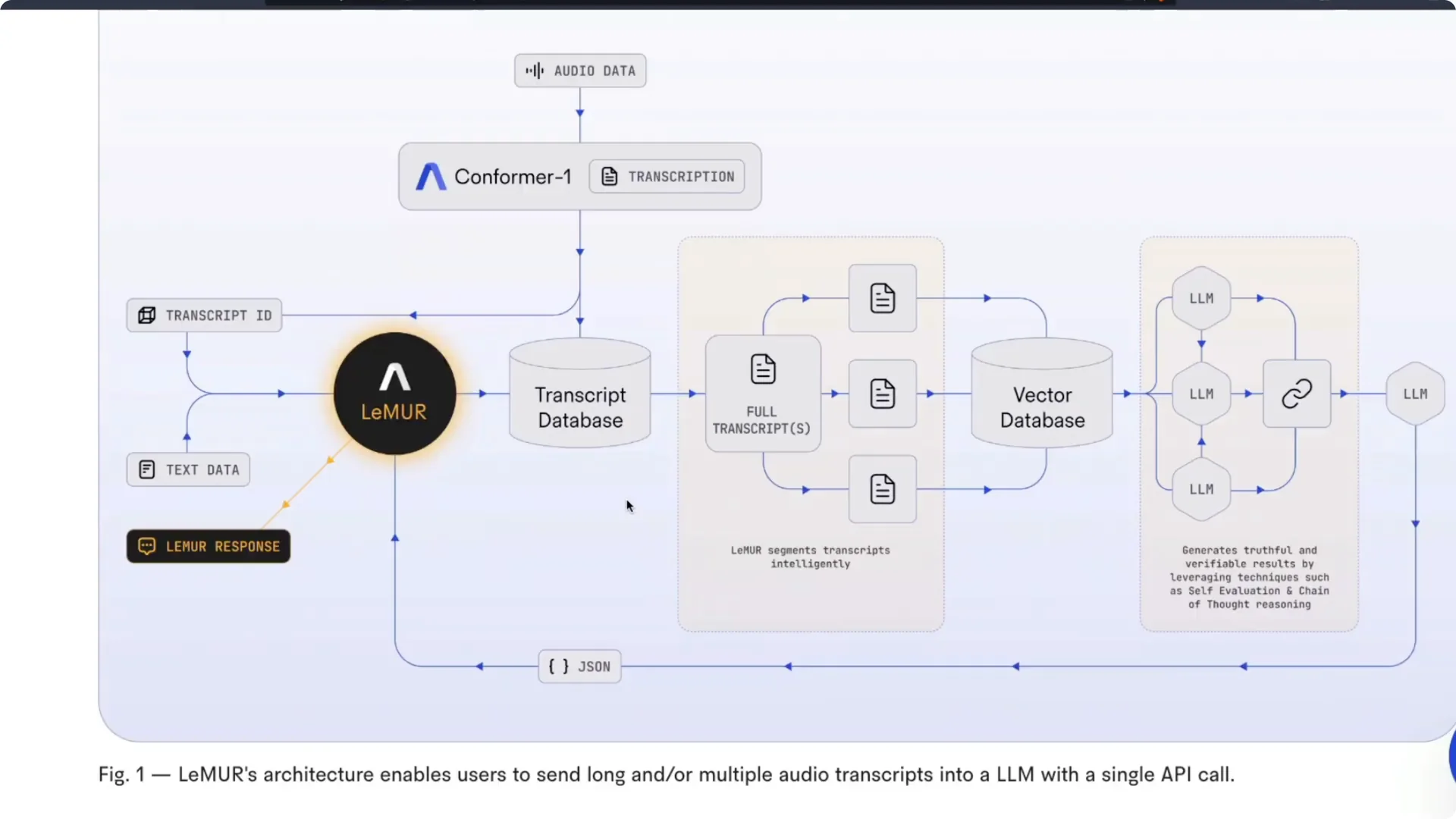
Audio is first transcribed by AssemblyAI’s Conformer model. The transcript is stored in a transcript database rather than being pushed directly to a large language model. LeMUR then segments the transcript into multiple parts in a way that is described as intelligent, though the exact strategy is not public.
Those segments are indexed in a vector database. Individual segments are passed to large language models for retrieval and reasoning. Results are stitched together using chain-of-thought prompting and self-evaluation.
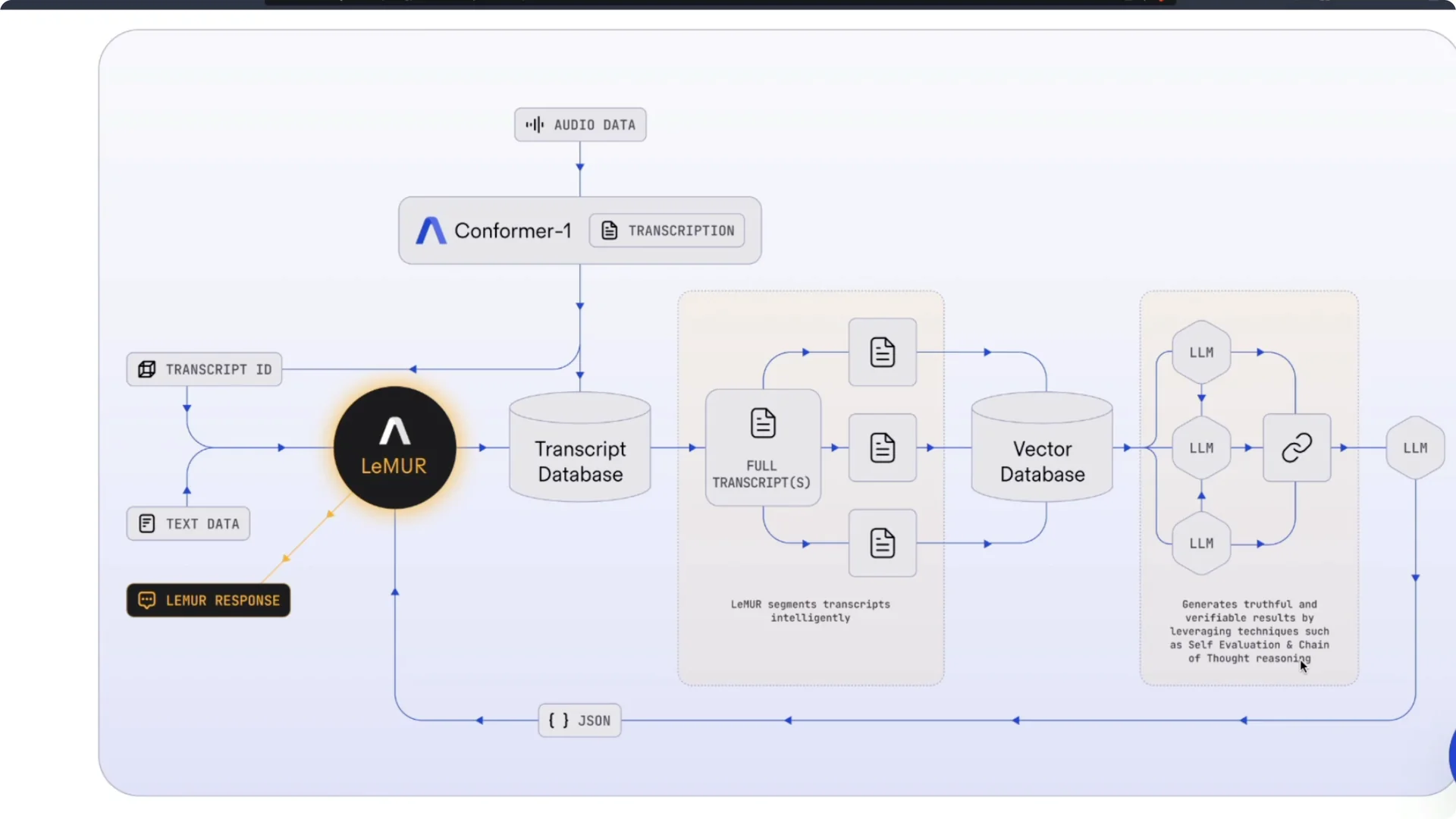
A final large language model composes the result and returns a LeMUR response. In practice, you send one big audio file and get back the answer to your task. It is a turnkey solution for long-form audio understanding.
If you want to compare with a Hugging Face speech-to-text path during prototyping, check this short guide to converting English speech to text with Hugging Face.
Hands-on with the AssemblyAI LeMUR Framework playground
I tested LeMUR on a 52 to 54 minute interview between Patrick Collison and Sam Altman. I pasted the YouTube URL into the LeMUR playground and asked it to transcribe. The entire transcript appeared and the transcription finished in under 10 minutes.
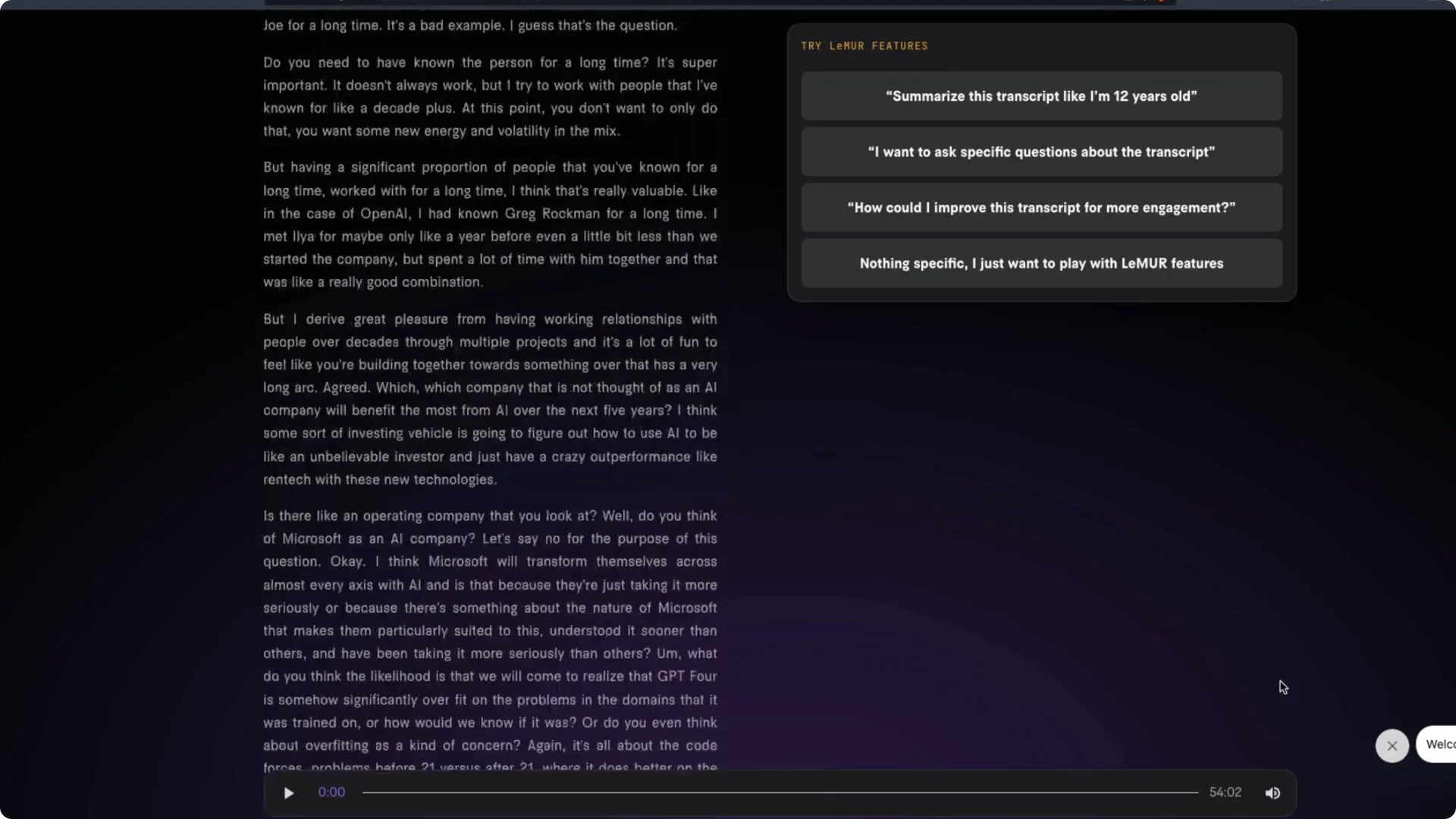
I then asked targeted questions against the transcript. For example, I asked what Sam Altman said about nuclear resources and its comparison with AI. The answer reflected the point that access to nuclear materials is more difficult because of complex permitting and regulatory processes.
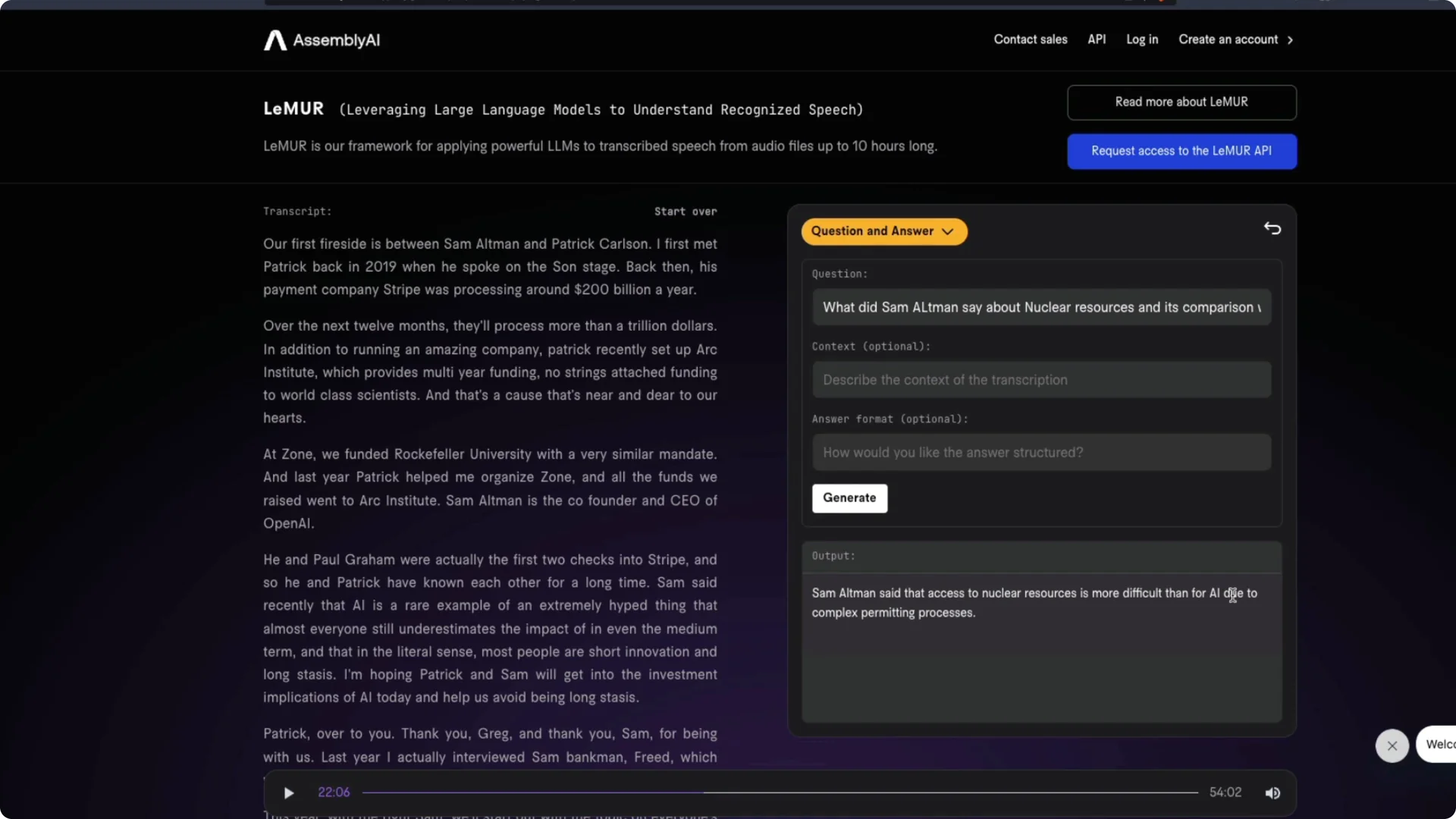
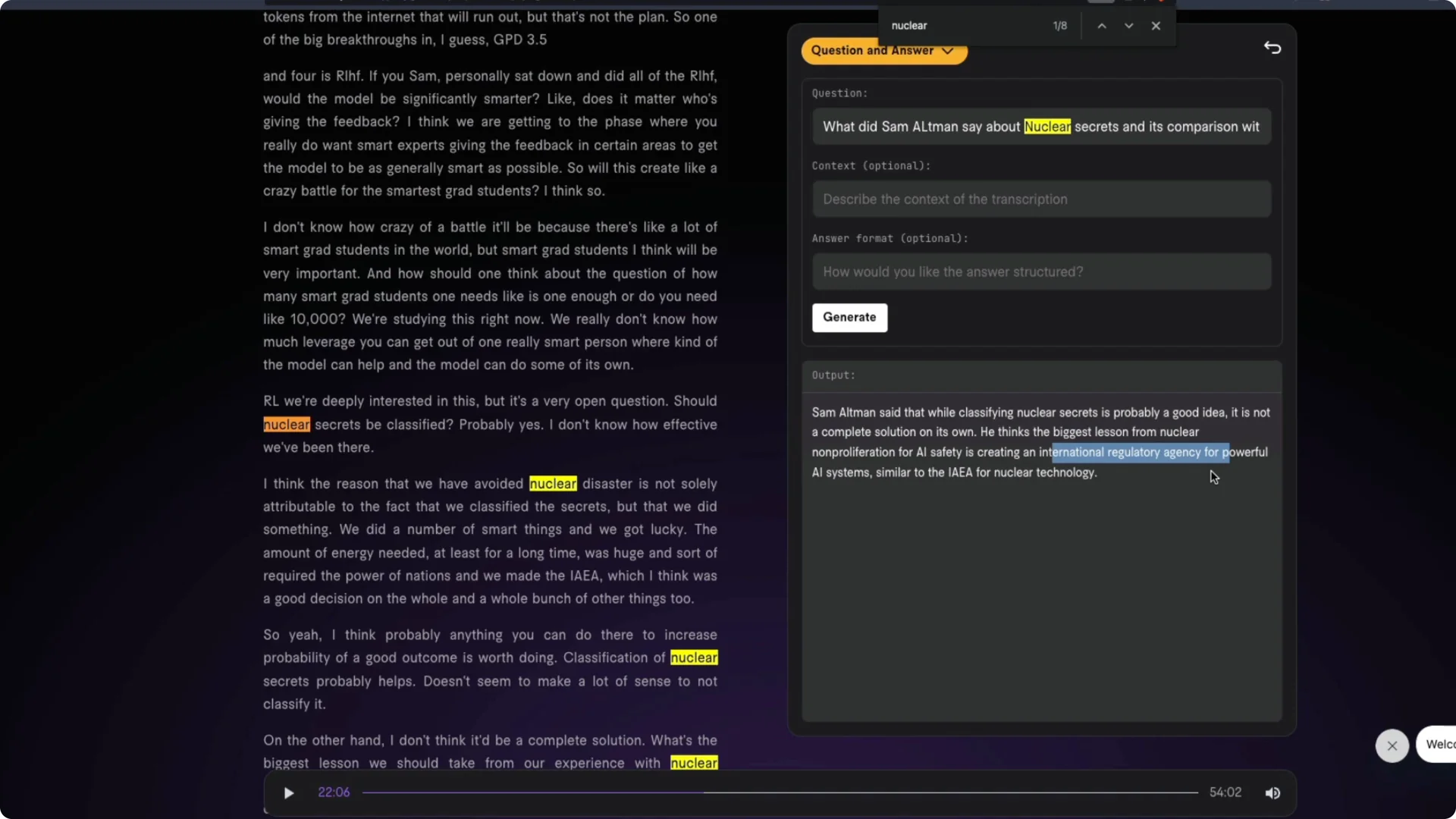
I refined the query to nuclear secrets and its comparison with AI. The system responded that classifying nuclear secrets is helpful but not sufficient and drew the main lesson as creating an international regulatory agency for powerful AI systems, similar to the IAEA for nuclear technology. That lines up well with the interview.
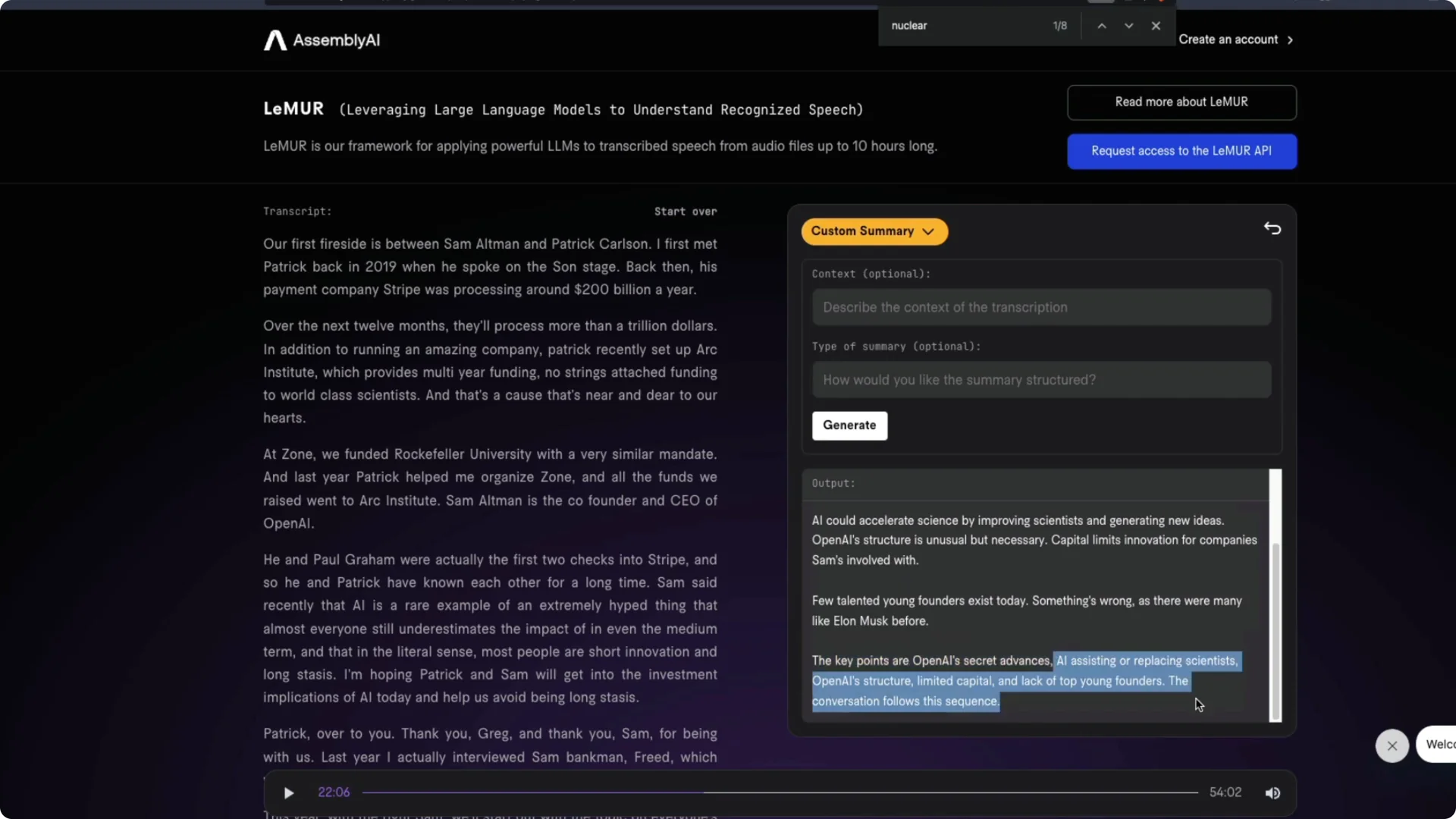
I also tried a summary. The summary quality was fine, though not perfect compared with what I expected from the first 25 minutes I had heard. The remainder of the conversation may have shifted focus, so results can vary with the full context.
Quick start – AssemblyAI LeMUR Framework playground
Open the LeMUR playground. Paste a YouTube link or upload an audio file.
Click to transcribe and wait for the transcript to complete. Ask specific questions on the transcript, request a summary, or try prompts like explain this like I am 12.
Use precise prompts tied to events or topics in the audio to reduce the chance of hallucination. When the topic is niche, reference names, terms, or timestamps from the transcript. Iterate with follow-up questions to get deeper context.
For building your own small project that chains speech-to-text with downstream prompts, see this step-by-step speech-to-text project in Python.
Use cases with the AssemblyAI LeMUR Framework
Students can process hours of lectures and ask questions on sections they missed. You can load multiple class recordings, then query for definitions, examples, or exam-style summaries. That shifts study time toward targeted review.
Customer support teams can inject domain context during analysis. For example, you can ask did the sales representative follow the exact prospecting procedure from the playbook and supply the playbook as context. Agents can then be evaluated against specific criteria rather than general guidelines.
The playground also includes sample audio like a multi-hour customer call and a TED Talk on dyslexia. You can test prompts such as how could the explanation be improved for high school students. Even when I pointed to the wrong transcript once, the system still produced coherent suggestions, though grounding the prompt in the right transcript is important.
Access and status of the AssemblyAI LeMUR Framework
LeMUR stands for large language models to understand and recognize speech. It is in early access with a waiting list. You can try the playground without API access.
When approved, you can call the API to transcribe and query long-form audio with one request. The core idea is to expand usable context through smart retrieval and reasoning rather than a single huge context window. It is a practical way to apply large language models to many hours of speech.
Resources
Read the early access details and architecture notes here: LeMUR early access overview.
Final thoughts
LeMUR makes it realistic to process around 10 hours of audio for summarization and Q&A in a single workflow. The architecture combines transcription, segmentation, retrieval, and reasoning to return grounded answers. The playground is fast, the Q&A quality is strong, and the approach points to a clear path for long-context audio understanding.