Meta AI has launched a new speech to text model that supports 1,100 languages. The demo is impressive, with people speaking in languages I had never heard about. Meta AI calls it Massively Multilingual Speech, or MMS, and it can support these languages.
The most important thing is that this model is open source. The model weights are available and anybody can download the model and start using it.
They have also given tips about fine tuning.
Meta MMS Speech Model overview
Yann LeCun, who is head of Meta AI, announced that the Meta MMS Speech Model can do speech to text and text to speech in 1,100 languages.
It can recognize 4,000 spoken languages. Before this I did not know that we have 4,000 languages.
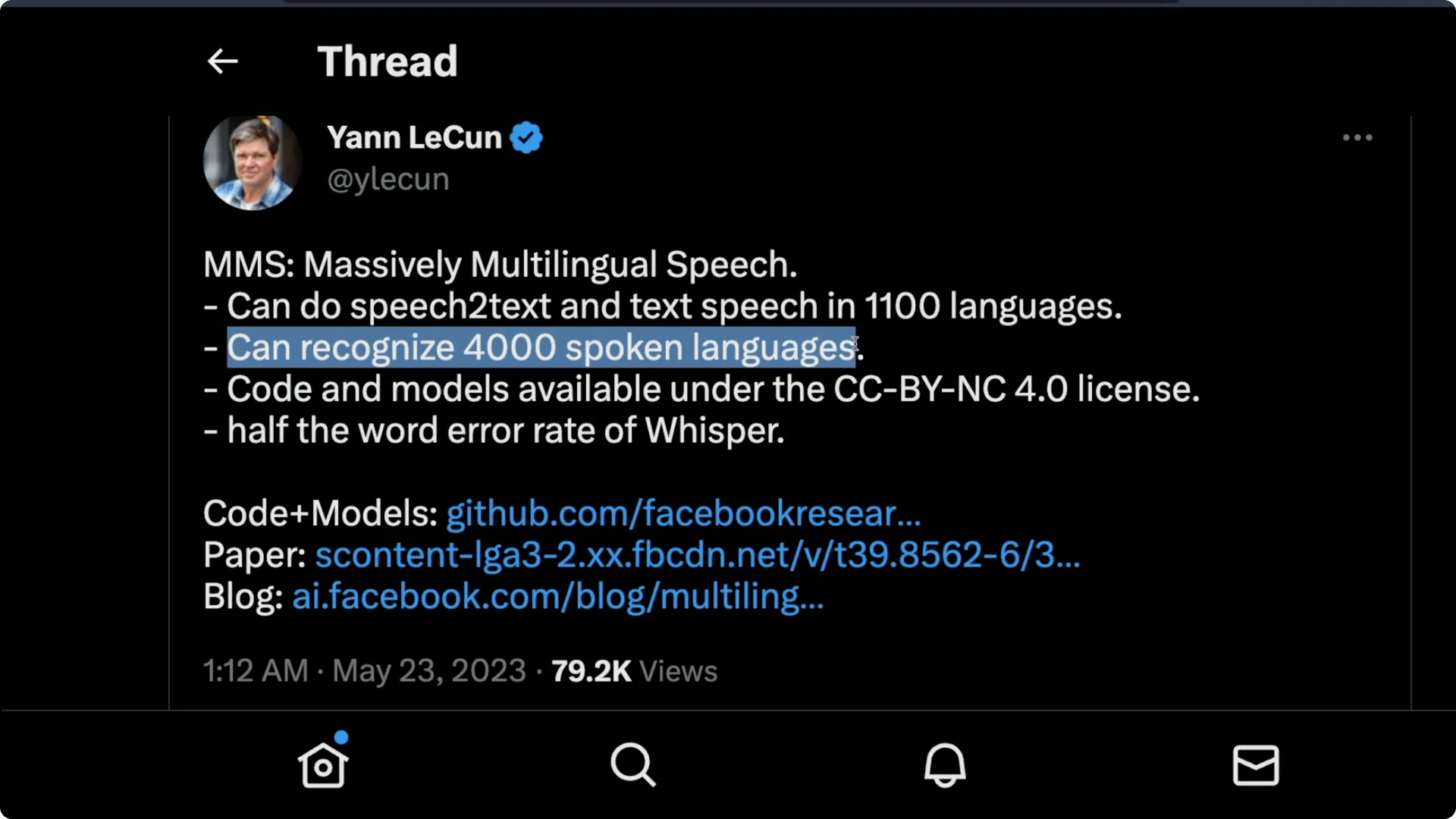
The code and models are available under a CC BY-NC 4.0 license. That is quite an open source license. This release makes it easy for anyone to get started.
Meta MMS Speech Model performance and coverage
OpenAI has got Whisper, and I am a big fan of Whisper. In a like for like comparison with OpenAI Whisper, they found that Meta’s MMS models trained on massively multilingual speech data achieve half the error rate.
MMS covers 11 times more languages than Whisper, which makes it a serious competitor for Whisper.

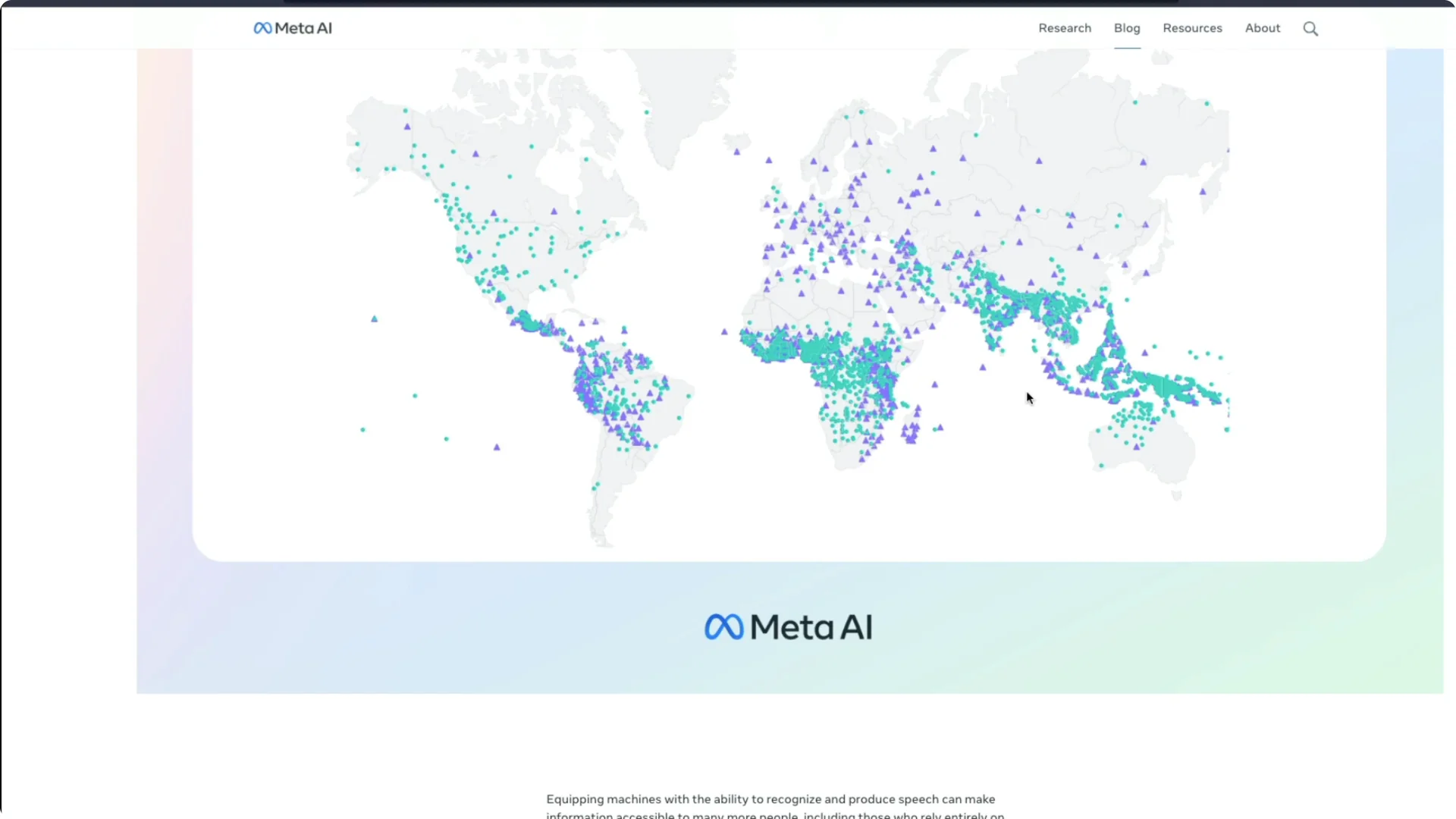
You can see details about error rates and performance percentages in their materials. The important part is the scale of language support. The world map view shows how broad the coverage is.
For a faster Whisper-based workflow, see our guide to speeding up Whisper transcription with JAX. It is helpful if you want a point of comparison for transcription performance.
Meta MMS Speech Model and No Language Left Behind
Facebook already had an initiative called NLLB – No Language Left Behind. Today you can see that this MMS model can support more than 1,100 languages. That is a big step toward broad multilingual access.
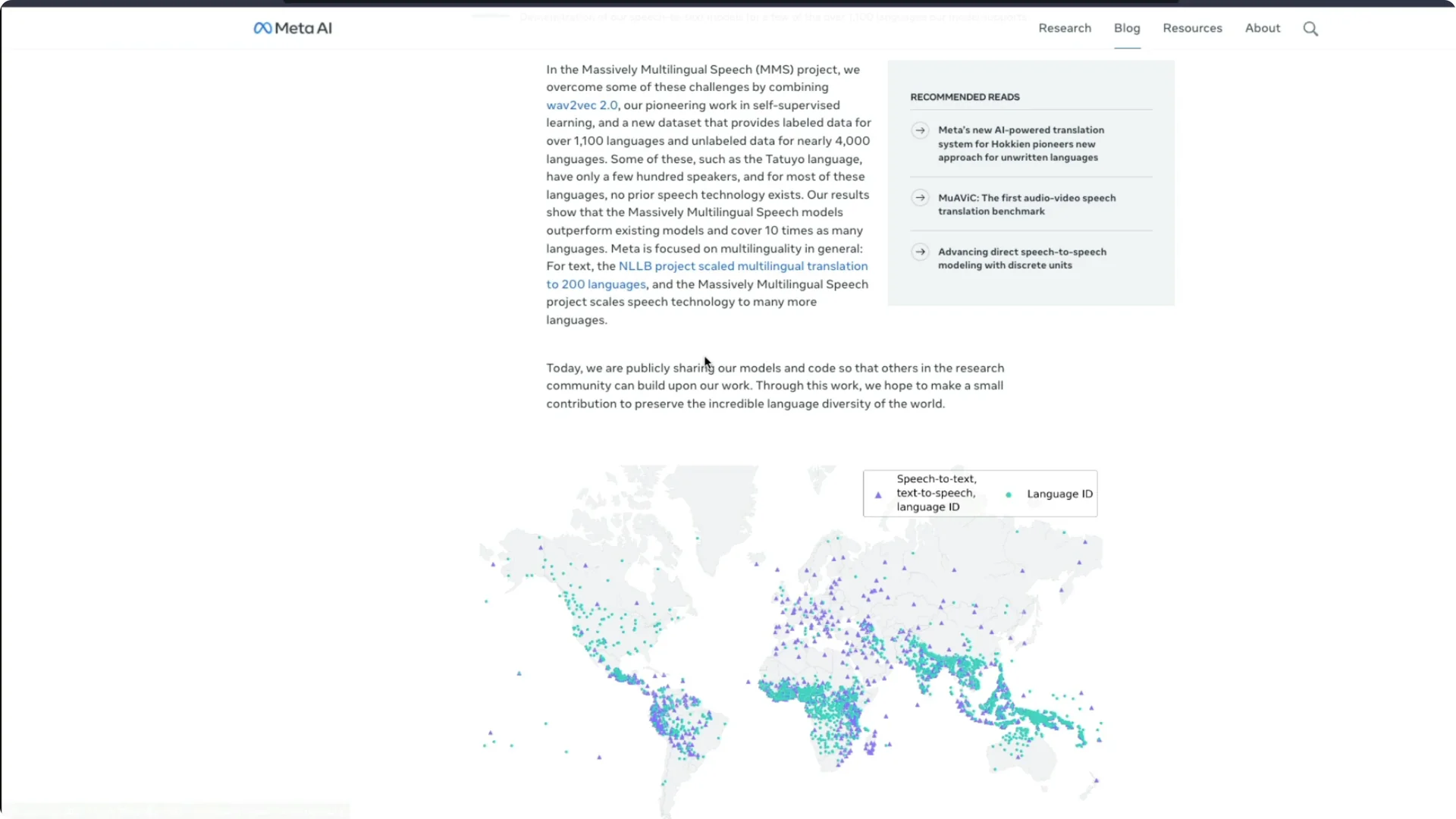
I find it brilliant to see representation for many languages that people do not even know exist.
From India to smaller speech communities worldwide, this coverage stands out. I would love to see more of these kinds of innovations from Meta.
How the Meta MMS Speech Model was built
According to them, they combined wav2vec 2.0 with their other dataset and labeled information. They created these new massively multilingual speech models that outperforms existing models.
It covers 10 or 11 times more languages than the existing models.
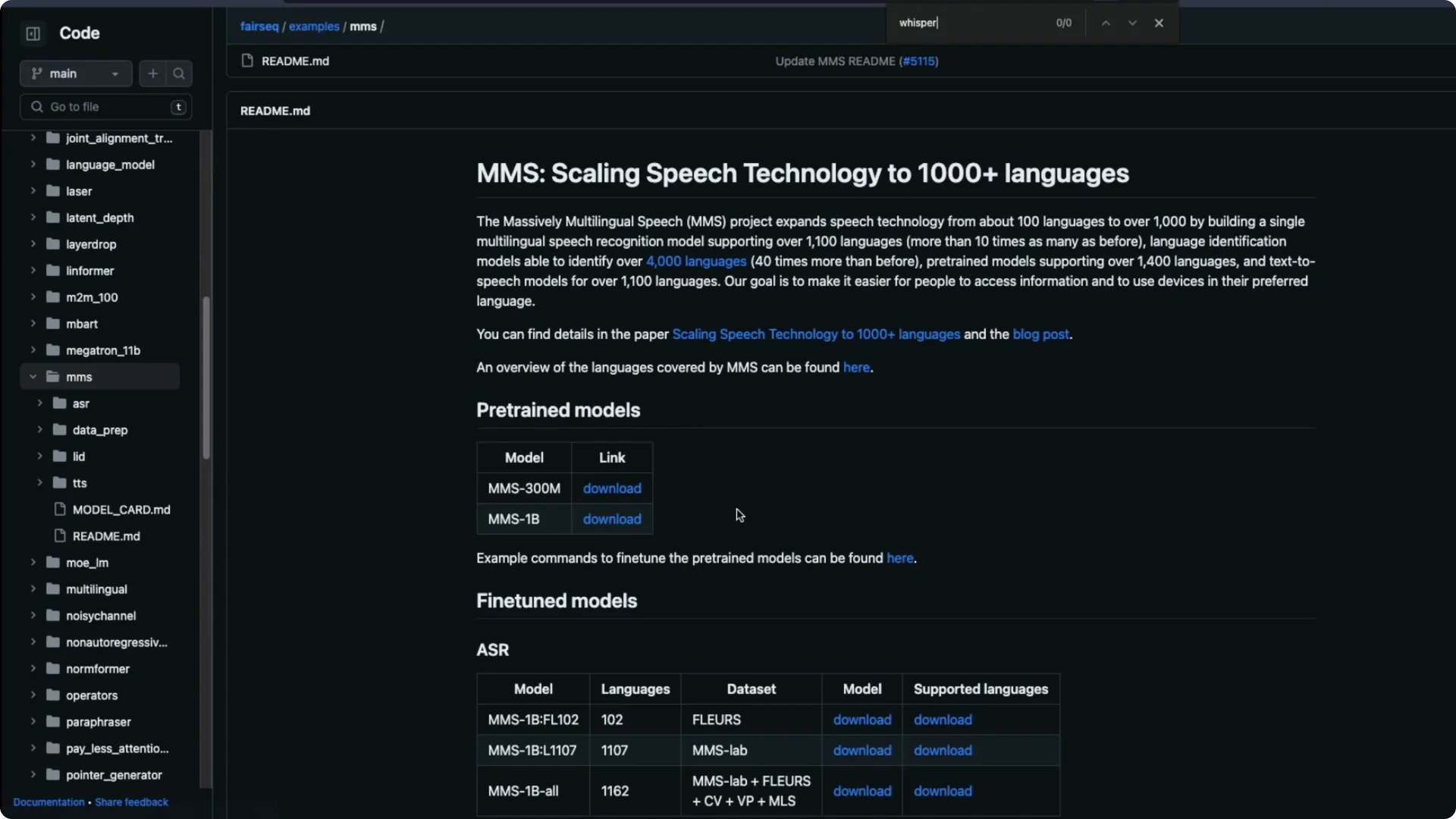
All the information about this model is released as part of their fairseq repository. You can download the PyTorch weights directly. They have released two checkpoints.
Meta MMS Speech Model checkpoints
There is a 300 million parameter model. There is also a 1 billion parameter model. You can choose based on your resource budget and target use.
They provide guidance on how to fine tune the models. If you have a language and want to cover that better, you can follow their instructions.
The versatility here already covers a lot.
Getting started with the Meta MMS Speech Model
Go to the fairseq MMS repository and grab the code and checkpoints. Download the 300M or 1B model weights and set up your PyTorch environment as described.
Start with the provided examples to confirm your setup.
If your goal is speech to text, load the model and run inference on a short audio sample. Verify the transcript for your target language. Then scale up to your dataset.
If your goal is text to speech, check the instructions they provide and test a basic synthesis.
Adjust configuration and voice parameters as available. Confirm the audio output quality for your language.
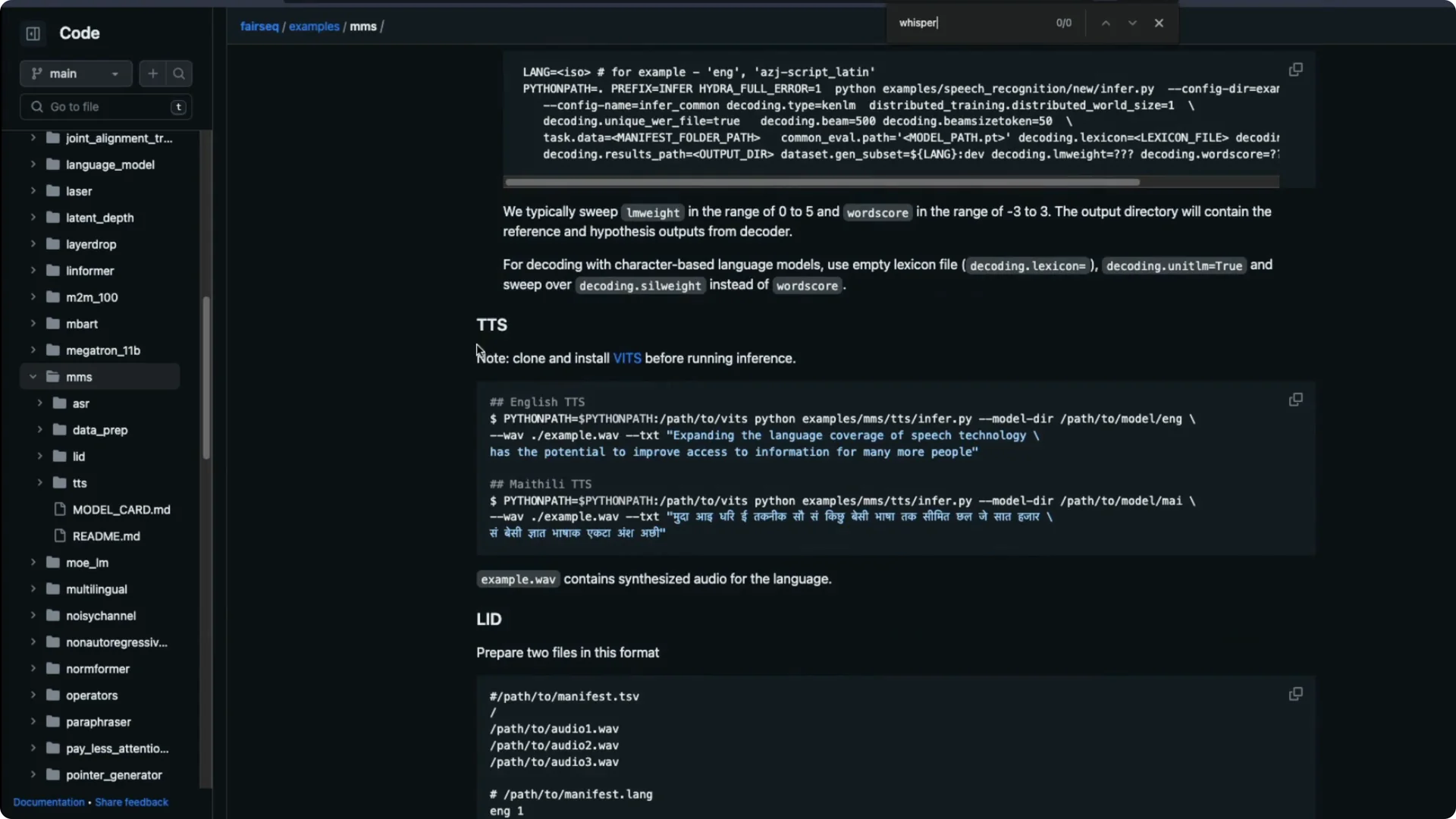
For fine tuning, prepare labeled audio data for your specific language or accent. Follow the repo’s fine tuning steps and monitor word error rate on a small validation set.
Once you get stable results, move to a larger dataset.
If you want more open source TTS options to compare with MMS, take a look at these free text to speech tools.
For a commercial voice solution, you can also explore ElevenLabs TTS.
Resources
Code and models – fairseq MMS
Paper – Massively Multilingual Speech

Final thoughts
This release is quite impressive. It does speech to text, text to speech, and more, with broad language coverage and strong error rates. If you want to try it out, the open source code and weights make it straightforward to start.