Meta’s new model, Seamless M4T, is absolutely nuts. I recorded an English audio saying I love making YouTube videos, and it instantly translated it into multiple languages. It did not stop at text translation, it also produced translated audio.
Forget audio quality for a moment. The fact that you can feed an input audio and get useful outputs across languages and modes is quite amazing. That is what made me sit up and pay attention.
What is Seamless M4T Multimodal Translation
Seamless M4T is an all-in-one massively multilingual and multimodal machine translation system released by Meta AI. It supports over 100 languages for speech input, 96 languages for text input and output, and about 35 languages for speech output. It brings multiple tasks into a single model.
Language Coverage and Core Tasks
You can speak in around 100 languages and get audio output in about 35 languages. For text, it handles input and output across 96 languages. That coverage alone is impressive.
This single model can do five tasks. It performs speech to speech translation, speech to text translation, text to speech, text to text translation, and automatic speech recognition for transcription. One model doing all five is the highlight for me.
For more context on multilingual speech research from Meta, check out our overview of Meta’s MMS speech model.
Hands-on: Using Seamless M4T Multimodal Translation on the Web

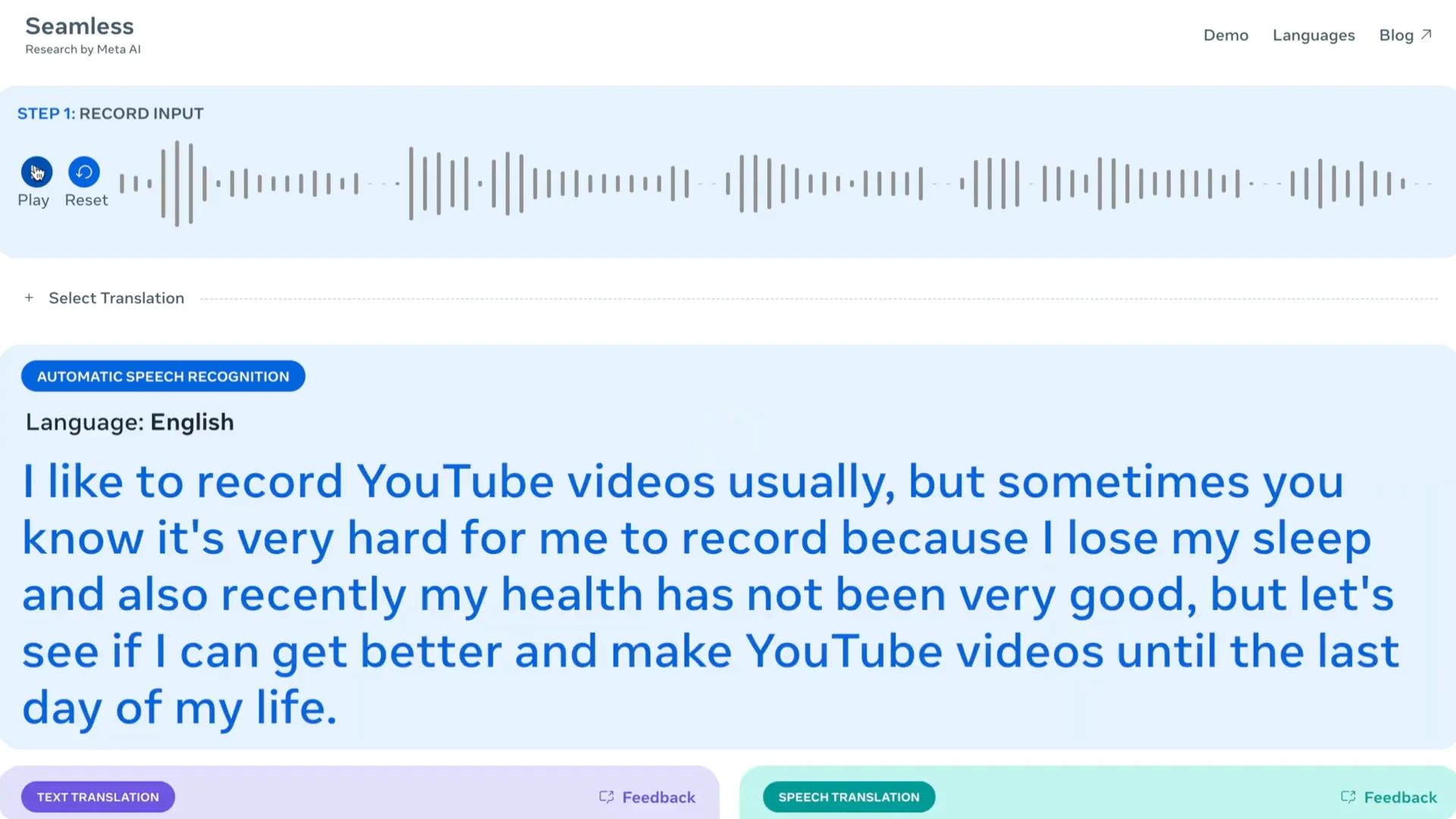
I tried the web demo and it worked well. I recorded a short English clip, picked a target language, and got both the transcription and the translation. It then generated the translated audio.
Step-by-step: Meta Demo
Open the demo, start recording, and speak your sentence or paragraph.
Stop recording, choose a target language, and run translation.
You will see the detected language, the transcription, the translated text, and you can play the translated audio.
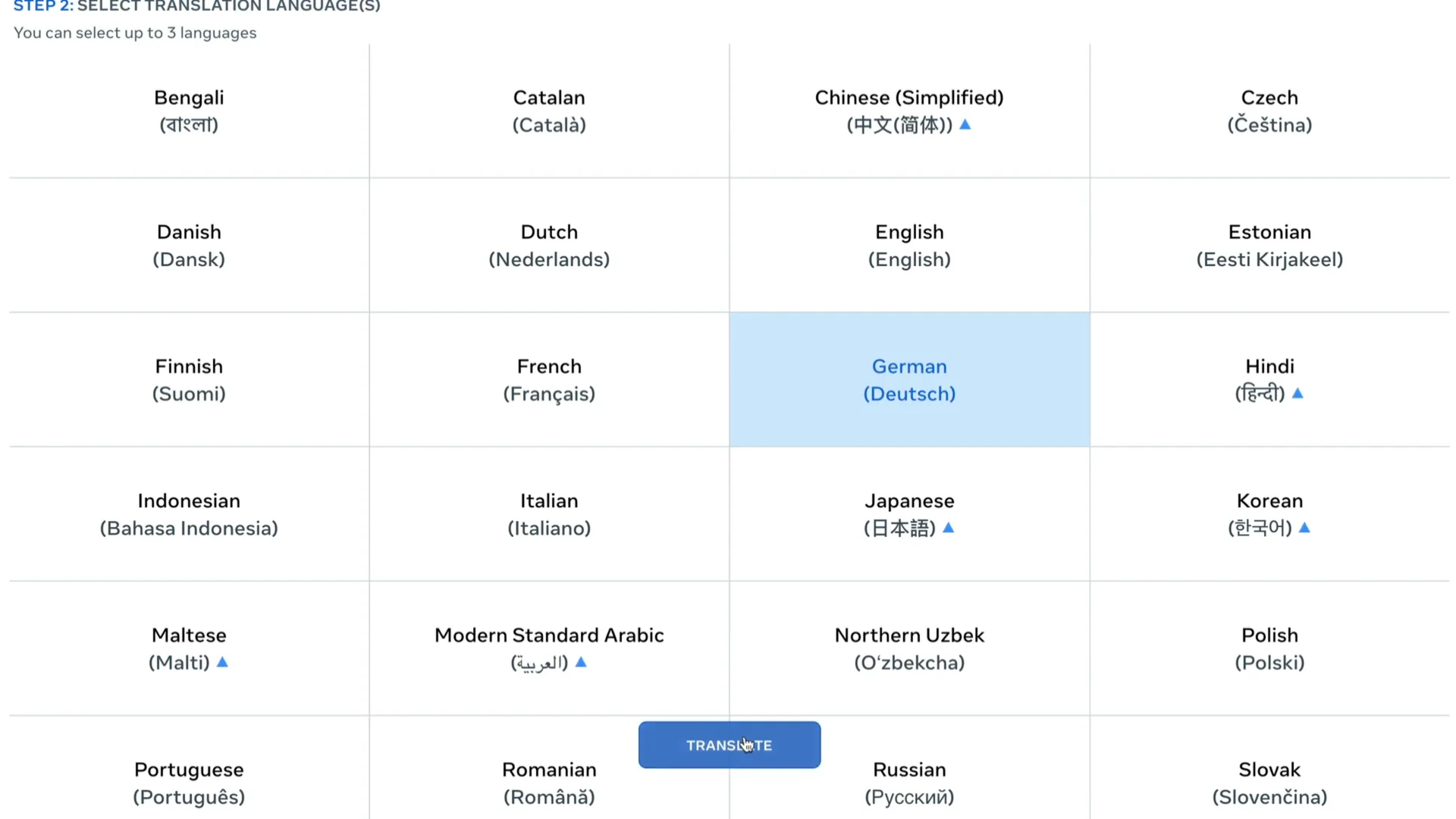
I translated my recording to German. The voice did not sound robotic to me, though I cannot verify the accuracy of the German content.
The interface also lists supported input and output languages, including a couple of Indian languages that sounded good in my tests, even if not perfect.
Step-by-step: Hugging Face Space
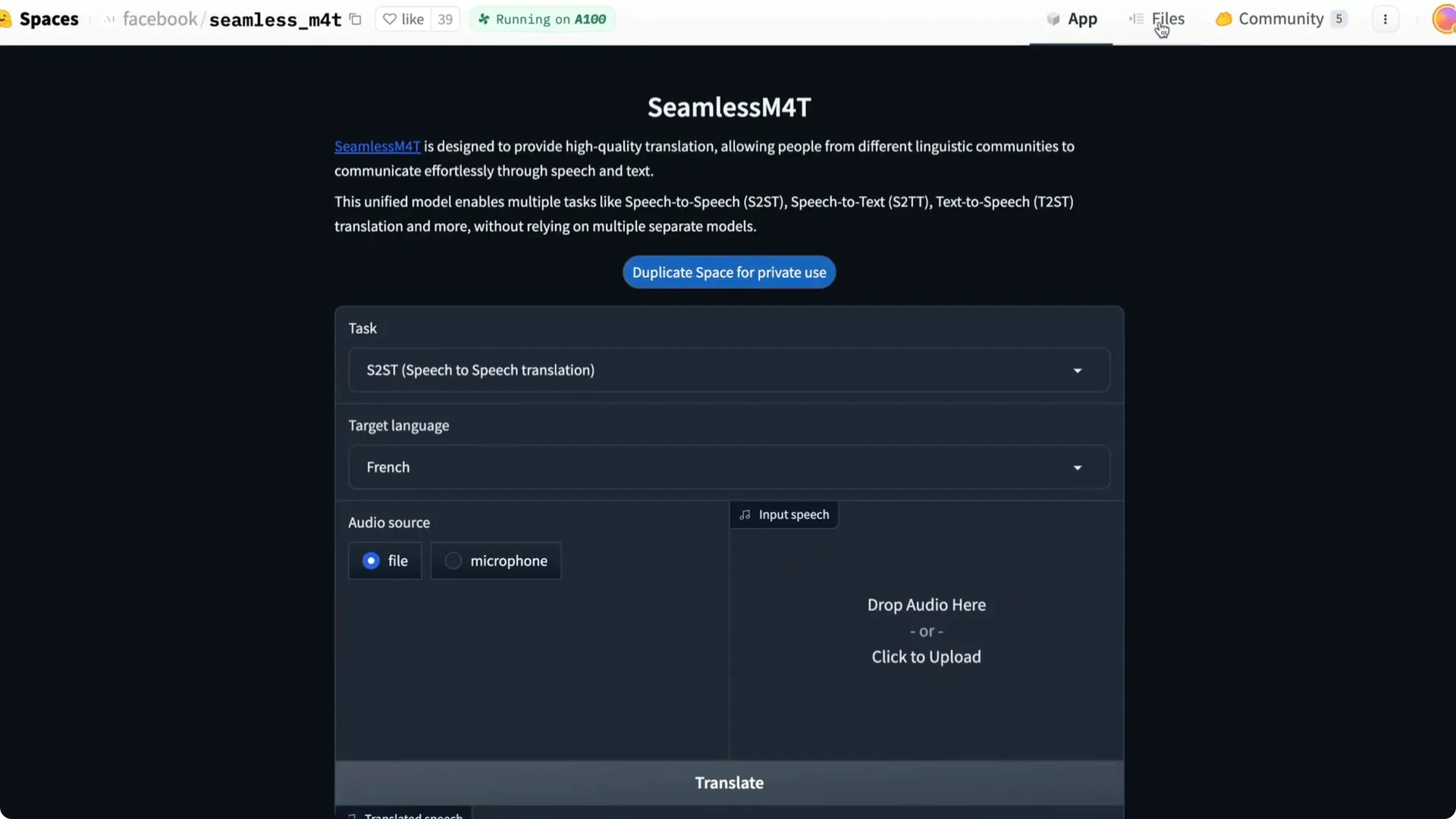
There is a Hugging Face Spaces demo as well. You can record from a microphone, upload a file, and see how the app processes it. The page includes the code and details on how it is being run.
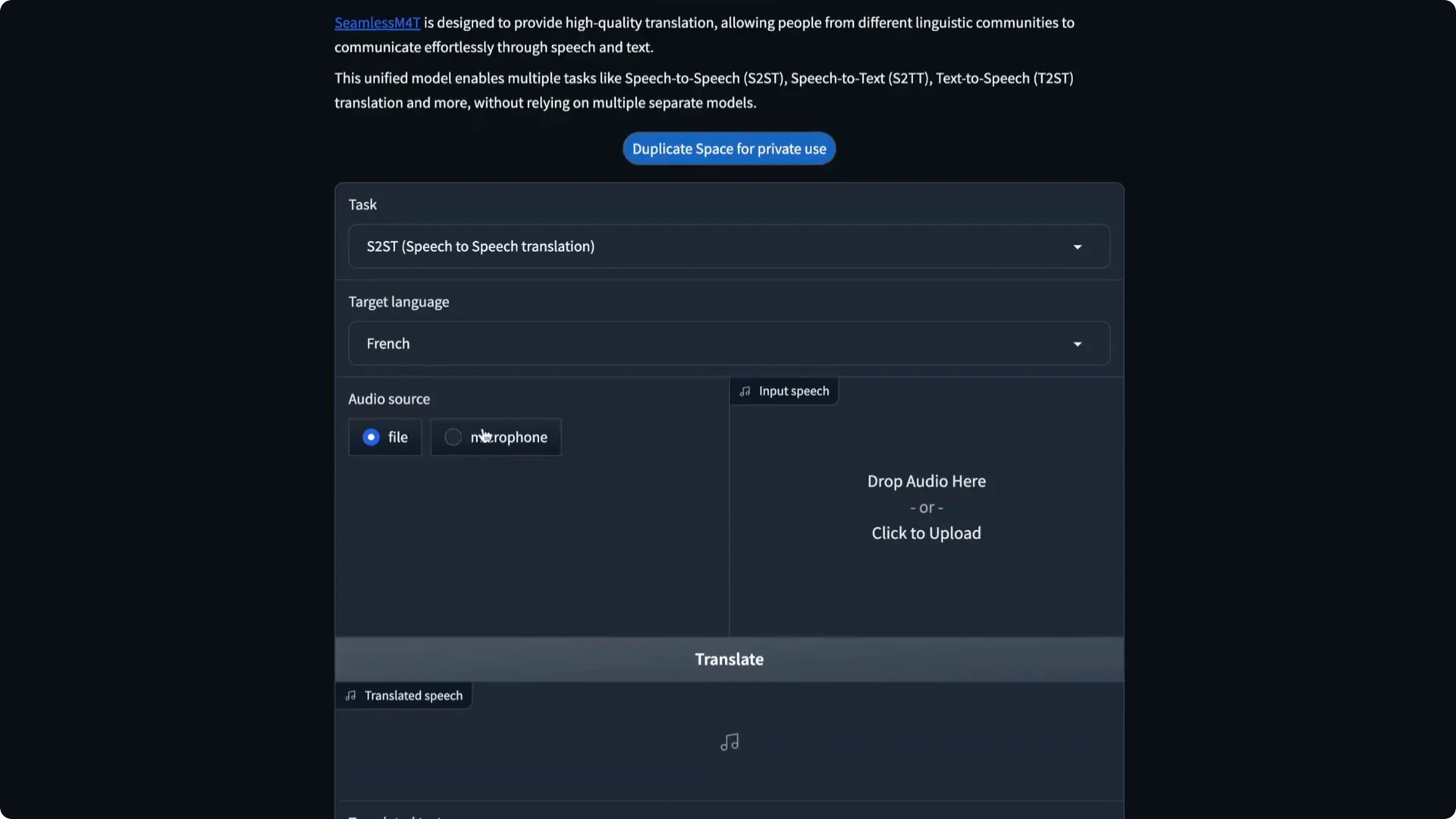
One catch is that the public space can have a queue. If you have your own GPU, you can duplicate the space and run it yourself. The current setup uses a Dockerfile and runs on an A100 machine.
If you are exploring voice creation beyond this model, you might like our guide to open-source text to speech tools.
Access, Weights, and Licensing
The model weights are already available. You should read the license carefully because it is currently for research use only. That means you cannot use it for commercial purposes like adding a clip in a game or an app.
I am happy the model and weights are released. Even if commercial use is not allowed yet, it is valuable for experimentation and learning. I would also love to test how far it can go on a free Colab setup.
If you are comparing options for production-ready voices, see our notes on commercial TTS services like ElevenLabs.
Performance Notes and Impressions
In one run, it detected my English input, produced a clean transcription, translated to German, and generated the final audio. Hearing the translated voice felt natural to me. The ability to switch between tasks without swapping models is what stood out.
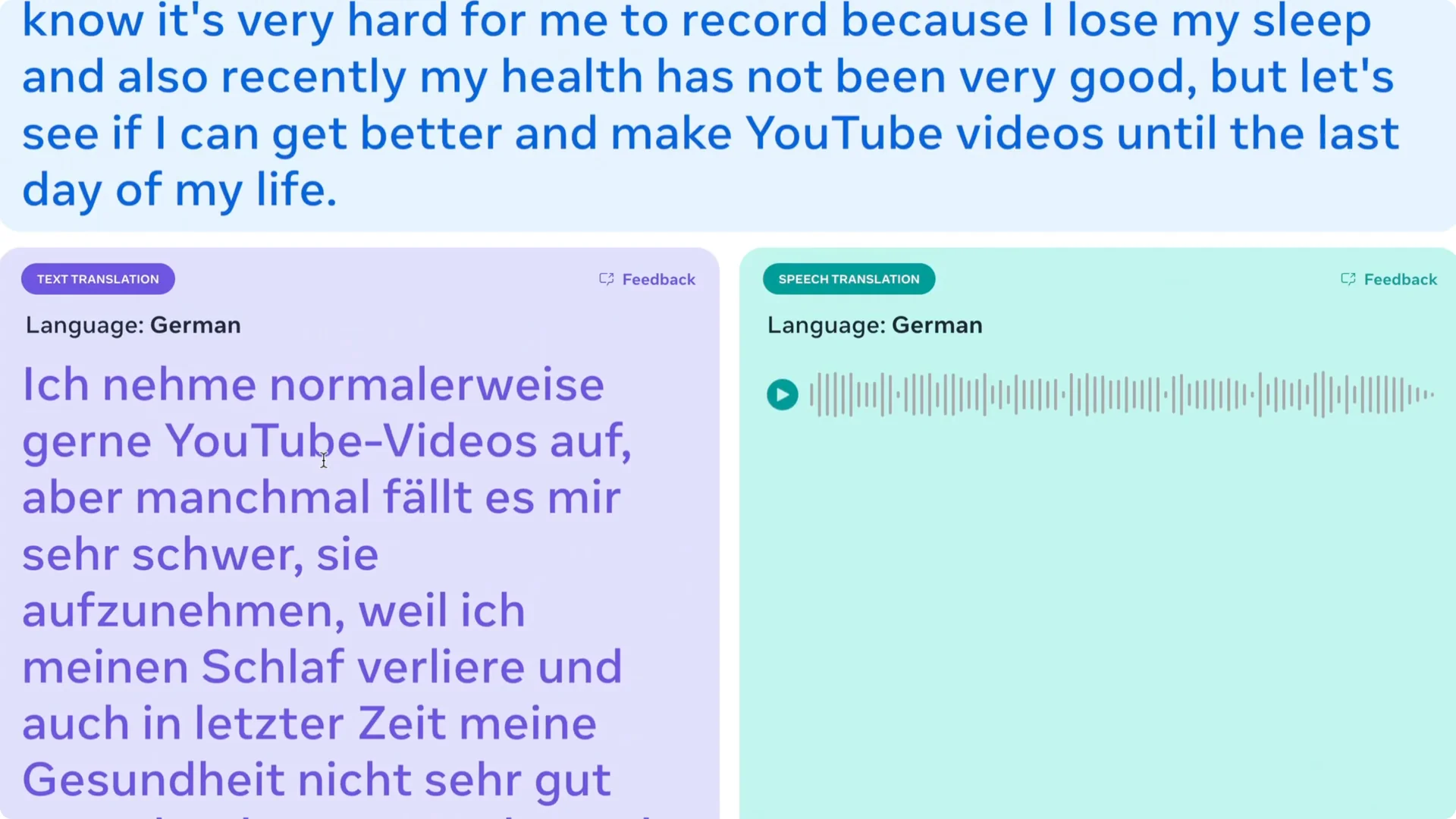
The combination of language coverage and task coverage is what makes this special to me. Meta keeps releasing strong research models and tooling. I am excited to see what developers and researchers build on top of this.
Resources
Try the Meta demo here: Seamless Meta AI Demo.
Experiment with the Hugging Face Space: Seamless M4T Hugging Face Spaces Demo.
Explore the codebase and docs: Seamless GitHub.
Final Thoughts
Seamless M4T brings five key translation and speech tasks into one model with broad language support. The demos show that it can transcribe, translate, and speak across languages with minimal setup. For research and prototyping, it is a must-try.